
2024-06-04
Parallelizing the un-parallelizable
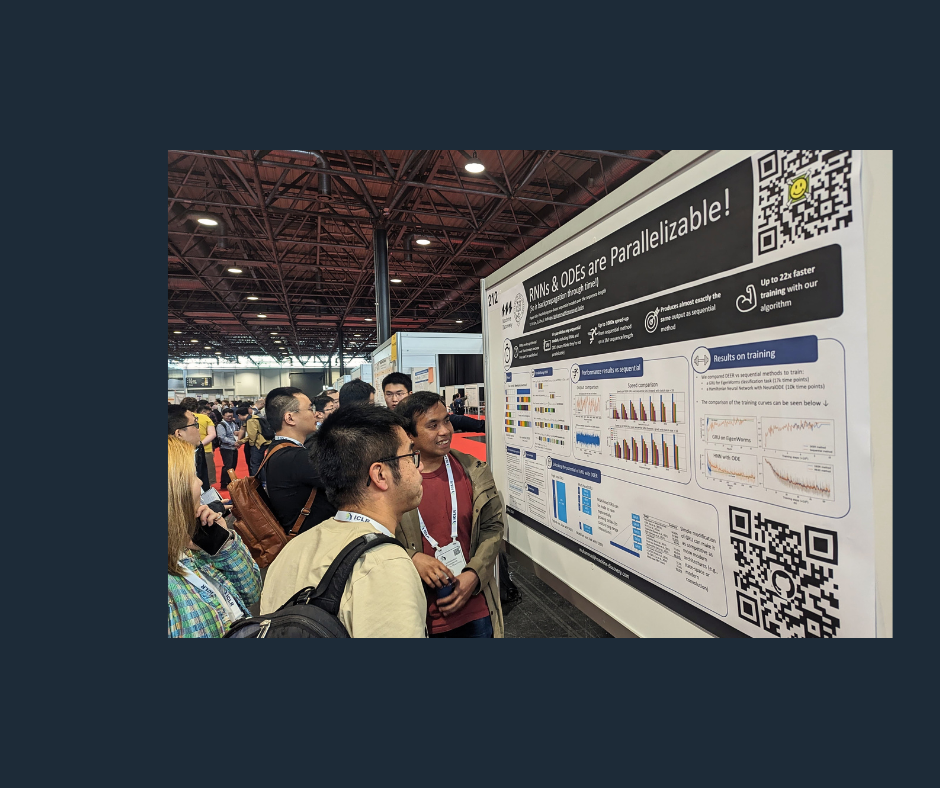
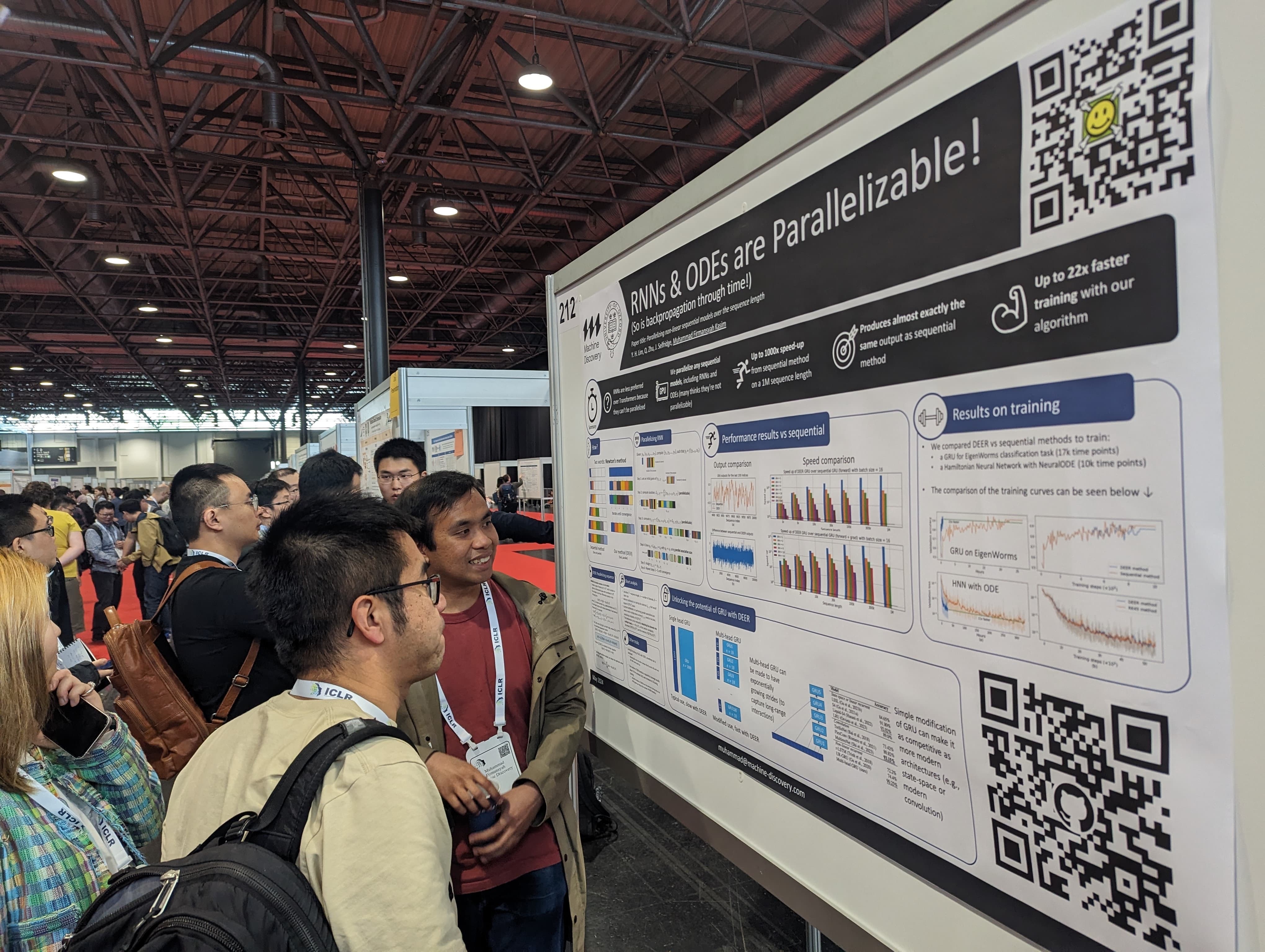
At the recent ICLR conference, we showed how it is possible to parallelize Recurrent Neural Networks.
We achieved a feat that many people think cannot be done: parallelizing Recurrent Neural Networks (RNN) over the time axis, achieving more than 100x speed ups. This is what our Chief Scientific Officer presented at the Twelfth International Conference on Learning Representations (ICLR) in May.
RNN is a very common class of neural networks architecture to process sequential or time series data. It has been successfully applied in many fields, including natural language processing, finance, neuroscience, and medical science.
Despite its wide applications, RNN is known to be slow to train because of its sequential nature. For example, to process a sequence of length 1000, it needs to do a sequential loop 1000 times. Think of it as reading a book: you must read each page before moving on to the next for it to make sense. RNN’s sequential nature is something that cannot be done efficiently in modern deep learning architectures, such as GPUs. It is slow to train, which is also a main contributing factor for why it’s less preferred over Transformer in building large language models.
In the work that we presented at ICLR 2024, we show that it is possible to parallelize RNNs, achieving orders of magnitude speed-up over the traditional sequential method on a GPU. The idea is based on a method that has existed for hundreds of years: Newton’s method. We translated Newton’s method to the problem of RNN and developed a new algorithm that can parallelize RNNs. The result is that we can evaluate RNN more than 100x faster than a sequential method, even for a sequence with length of 1M. Further details can be found in our paper.
Our method is not without limitations. Currently the method is limited to a small number of dimensions and it consumes large amounts of memory. These limitations prevent its use in interesting applications, presenting some challenges that need to be overcome in the future. Despite its limitations, we show that it is possible to parallelize the un-parallelizable RNN! This research generated a great discussion during our poster presentation at ICLR, furthering the importance of this work.